
こんにちは。ポン吉です。
ラズパイ4登場により、機械学習モデルを動かしやすい時代になりましたね。でも、ラズパイにAI推論させるにはスペックとして限界があります。それでもラズパイでエッジコンピューティングしたい!
そんなあなたにJetson Nano!


それは言っちゃダメー!!(笑)ラズパイがいいんだ!
そんな「ラズパイ愛」あふれる方に、ラズパイのAI機能を強化(ドーピング)するアイテムを紹介。その名はIntel Neural Compute Stick2(NCS2)。下記写真の青いデバイスです!
今回の記事を読めば「ラズパイ+NCS2」によるAI画像分析を簡単に実行できるようになります。


下記記事で来客者インターフォン画像をリアルタイム分析しLineに通知で紹介した内容です。

今回のテーマはこちら!
- Intel Neural Compute Stick2(NCS2)をRaspberry Pi 4 で使うためのセットアップ方法を紹介
- pythonプログラムを書いて人物画像から「性別・年齢・表情」を分析しよう(かっこよく)
Intel公式サイトでは「プラグ&プレイで素早く簡単に利用可能」と記載がありますが、現実はそんなに甘くないです(汗)。ラズパイで使うのがマニアックすぎる?のか検索しても情報が少ない。ラズパイでC言語を使いたい人は「ほぼいない」と思いますが、Pythonで使う情報があまりない。
C言語じゃなくてPythonで動かしたいんだよ~ イライラ!
だよね~ 今の時代ではC言語知らない方も多いと思います
Raspberry PiのPiは「Python interpreter」。俺はPythonで動かしたいんだ!という方にお役に立てれば・・と思い情報を公開していきます。
それではやってみましょう~♪
OpenVINO+NCS2+ラズパイでできること

OpenVINOとは?
OpenVINOはIntelが無償で提供しているソフトウェアです。Intel製CPUのディープラーニング推論を簡単かつ高速に実行できるツールです。
Intel製CPUが前提となっているためラズパイ単体でOpenVINOは使えません。Intel製NCS2をラズパイに接続することでラズパイでもOpenVINOが使えるようになります!
OpenVINOでできること
無償ですぐ使えるディープラーニング学習済みモデルがたくさんあります。Intelサイトから一部抜粋し画像ギャラリーで紹介します。







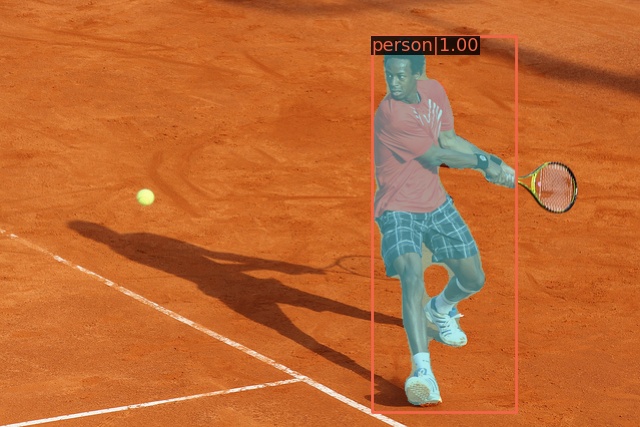











Intelサイトにあるデモ画像集 ※Intel OpenVINOサイト引用
人物検知は監視カメラでも活用中!
姿勢検知はアイデア次第では使えそう!
ちなみにOpenVINOにはディープラーニングの学習をする機能はありません。学習済みモデルを高速に動かすためのツールです。他のフレームワークで学習されたモデルをOpenVINO形式に変換し動かすことも可能です。
【準備】Intel Neural Compute Stick 2 (NCS2)の環境構築

難易度(内容理解):★★★★★
最初は意味不明でも問題なし。動くものを改造しながら学習するのがおすすめ!
動かすので苦労するとモチベーション落ちますからね。
内容を理解するのは難しい・・・という意味で高難易度としています。動かすだけならコピペで誰でもできるよう記事を記載したのでご安心下さい。
細かいOpenVINOによるモデルの使い方や、OpenCVによる画像処理について理解するのは後追いでも構いません。楽しく試してみましょう。
必要な機材
かなり重い演算処理をさせることになりますので「ラズパイ4+NCS2」の組み合わせを推奨。CPUも高熱になりますので冷却ファンも合わせて準備しましょう。この3種の神器を揃えればラズパイでエッジAIコンピューティングが実現できます!



NCS2販売終了?
NCS2は販売終了との情報が出てきています。また、USBタイプでNCS3などの後継機種の予定もなし。今後は更に入手困難になると思いますので、ラズパイでドーピングを検討されている方はご注意下さい。
ラズパイだけでも品薄だってのに!
Intelさん USBタイプのNCS3の計画をお願いします…
ラズパイ自体も品薄で購入が難しい状況が続いています。ラズパイの在庫と価格をリアルタイム確認できるページを作りました。ラズパイを購入しようとしている方は是非参考にしてみてください。

Intel Neural Compute Stick 2 (NCS2)の仕様


Intelカラーの青いヒートシンクに包まれています。放熱性にも期待ができそう。質感は高いです!
スペック情報
- 製品名: Intel Neural Compute Stick 2
- 搭載プロセッサ: Intel® Movidius™ Myriad™ X Vision Processing Unit 4GB
- プロセッサー ベース動作周波数: 700 MHz
- USB規格: USB 3.0 Type-A
DNN ハードウェアアクセラレータを搭載しOpenVINO™ツールキットに対応

ファンなどはなく放熱を考慮した穴が4つ空いています。学習済みモデルを用いて推論させる際、かなり高温になるので注意しましょう。

ラズパイ4のUSBに接続するとこんな感じになります。図を見て頂くとわかるのですが、このドーピングデバイス・・・非常に厚み・幅があるため4つのUSBポートがほぼ使えなくなります…
必要に応じてUSB延長ケーブル等の導入を検討下さい。なるべく空気のフロー効率を上げるため地面から話した上段中央に接続しています。
Raspberry Pi OS (32bit) buster をセットアップ
2022/6時点、OpenVINOは最新Raspberry Pi OS であるbullseye や64bitに対応していません。正確に言うと、ラズパイ上でソースをコンパイルすることで使えるようにすることもできますが、半日ほどかかる苦行になります。そこまでして動かすこともないので、今回は32bit Raspberry Pi OS busterを使ってサクッと簡単に環境構築します。
Raspberry Pi imagerを使ってSDカードに書き込みます。Raspberry Pi OS (Other)を選んで一番下2つ(Legacy)と書いてあるものがBusterになります。GUIデスクトップ版かCUIコマンドライン版かは、用途に応じてお選びください。

ラズパイ初期セットアップの詳細は、下記記事にて記載していますのでご参考まで。

Raspberry Pi に OpenVINO環境をセットアップ

intel公式サイトのセットアップ手順に従ってコピペで動かせるように説明します。参照元情報として確認したい方は下記リンクから参照してください。

ここ見てもラズパイ用のダウンロード媒体の情報がない
どこでラズパイ用の媒体入手するんだ!?ムキー!
よって、ネットでラズパイ向けのOpenVINOで動作可能な最新バージョンを探しにいきます。現時点では l_openvino_toolkit_runtime_raspbian_p_2021.4.752.tgz が見つかりました。こちらを使って環境構築を進めます。
sudo mkdir -p /opt/intel/openvino
mkdir ~/download
cd ~/download
wget https://storage.openvinotoolkit.org/repositories/openvino/packages/2021.4.2/l_openvino_toolkit_runtime_raspbian_p_2021.4.752.tgz
sudo tar -xf l_openvino_toolkit_runtime_raspbian_p_2021.4.752.tgz --strip 1 -C /opt/intel/openvino
echo "source /opt/intel/openvino/bin/setupvars.sh" >> ~/.bashrc
source /opt/intel/openvino/bin/setupvars.sh
sudo usermod -a -G users "$(whoami)"
sh /opt/intel/openvino/install_dependencies/install_NCS_udev_rules.shNCS2は最初からRaspberry Piに接続したまま作業して頂いて構いません。上記をコピペして貼り付ければセットアップ完了です。特に再起動等も必要なく使えるようになります。
【実践】サンプル画像から顔認識して「性別・年齢・感情」を一気に分析!
「フリー写真素材サイト:ぱくたそ」さんから素敵なお姉さんの画像を使わせていただきます。

こちらの画像に学習済みモデルを使って「ラズパイ+NCS2」でAI分析していきましょう。
OpenCV環境のセットアップ
インテルのC言語サンプルは一切使いません。学習済みモデルをpythonで分析する方法を紹介します。
sudo apt update
sudo apt install -y python3-pip
sudo apt install -y libopencv-dev
sudo apt install -y python3-numpy
pip3 install pillowインストール所要時間
初期セットアップ済みのラズパイ4で、約8分程度の時間がかかります。
OpenCVの使い方は下記記事にて詳細な解説をしています。あわせて参考にしてみてください。

OpenVINO学習済みモデルのダウンロード
OpenVINOのモデルから、使いたい3つのデータをダウンロードします。NCS2はFP16しか対応していないため注意してください。
cd ~/
wget https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.4/models_bin/3/face-detection-retail-0004/FP16/face-detection-retail-0004.bin
wget https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.4/models_bin/3/face-detection-retail-0004/FP16/face-detection-retail-0004.xml
wget https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.4/models_bin/3/age-gender-recognition-retail-0013/FP16/age-gender-recognition-retail-0013.bin
wget https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.4/models_bin/3/age-gender-recognition-retail-0013/FP16/age-gender-recognition-retail-0013.xml
wget https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.4/models_bin/3/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.bin
wget https://storage.openvinotoolkit.org/repositories/open_model_zoo/2021.4/models_bin/3/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml
学習済みモデル情報
- 顔の認識 : face-detection-retail-0004
- 年齢・性別の認識 : age-gender-recognition-retail-0013
- 感情の認識 : emotions-recognition-retail-0003
PythonによるAI分析プログラムを実行

以下のサンプルコードをそのままコピーして使えば分析できると思います。JELLYWAREクラゲさんのサイトのソースをベースに、最新版OpenVINOでも動作するようにして複数の分析処理を組み合わせてみました。ありがとうございます!
贅沢に3つの複数モデルで分析処理を実行していきます。また、画像にフレームの枠を付けたり、よくある四角い枠での認識ではなく画像透過処理を施しながらかっこよく?仕上げます。
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
import argparse
import sys
from openvino.inference_engine import IECore
# 画像読み込み
frame_png = cv2.imread("frame_main.png", cv2.IMREAD_UNCHANGED)
face_png = cv2.imread("frame_face.png", cv2.IMREAD_UNCHANGED)
gender_png = cv2.imread("frame_gender.png", cv2.IMREAD_UNCHANGED)
# コマンド引数の設定
parser = argparse.ArgumentParser(description='Object Detection')
parser.add_argument('-i',type=str,help='input JPG file path.(FullPath)',required=True)
parser.add_argument('-o',type=str,help='output JPG file path.(FullPath)',required=True)
args = parser.parse_args()
input_file_path=args.i
output_file_path=args.o
# IEコア初期化
ie = IECore()
# ターゲットデバイスの指定
devname='MYRIAD'
# モデルの読み込み(顔検出)
net = ie.read_network(model='face-detection-retail-0004.xml',
weights='face-detection-retail-0004.bin')
exec_net = ie.load_network(network=net,device_name=devname)
# モデルの読み込み(感情分類)
net_emotion = ie.read_network(model='emotions-recognition-retail-0003.xml',
weights='emotions-recognition-retail-0003.bin')
exec_net_emotion = ie.load_network(network=net_emotion,device_name=devname)
# モデルの読み込み(年齢・性別)
net_gender = ie.read_network(model='age-gender-recognition-retail-0013.xml',
weights='age-gender-recognition-retail-0013.bin')
exec_net_gender = ie.load_network(network=net_gender,device_name=devname)
### 半透明画像を合成する関数 ###
def overlayImage(src, overlay, location):
overlay_height, overlay_width = overlay.shape[:2]
# 背景をPIL形式に変換
src = cv2.cvtColor(src, cv2.COLOR_BGR2RGB)
pil_src = Image.fromarray(src)
pil_src = pil_src.convert('RGBA')
# オーバーレイをPIL形式に変換
overlay = cv2.cvtColor(overlay, cv2.COLOR_BGRA2RGBA)
pil_overlay = Image.fromarray(overlay)
pil_overlay = pil_overlay.convert('RGBA')
# 画像を合成
pil_tmp = Image.new('RGBA', pil_src.size, (255, 255, 255, 0))
pil_tmp.paste(pil_overlay, location, pil_overlay)
result_image = Image.alpha_composite(pil_src, pil_tmp)
# OpenCV形式に変換
return cv2.cvtColor(np.asarray(result_image), cv2.COLOR_RGBA2BGRA)
### メイン処理 ###
# 画像ファイルを読み込む
frame = cv2.imread(input_file_path)
# 入力データフォーマットへ変換
img = cv2.resize(frame, (300, 300)) # サイズ変更
img = img.transpose((2, 0, 1)) # HWC > CHW
img = np.expand_dims(img, axis=0) # 次元合せ
# 推論実行(顔認識)
out = exec_net.infer(inputs={'data': img})
# 出力から必要なデータのみ取り出し
out = out['detection_out']
out = np.squeeze(out) #サイズ1の次元を全て削除
# 画像から検出された顔領域に対して一番認識率の高い一人分のみ対象に選択
detection = out[0]
# 顔の認識率を取得
confidence = float(detection[2])
# バウンディングボックス座標を入力画像のスケールに変換
xmin = int(detection[3] * frame.shape[1])
ymin = int(detection[4] * frame.shape[0])
xmax = int(detection[5] * frame.shape[1])
ymax = int(detection[6] * frame.shape[0])
# 顔認識率のconf値が0.4より大きい場合のみ感情・性別・年齢の推論を実施
if confidence > 0.4:
# 画面外座標の場合エラーにならないよう補正
if xmin < 0:
xmin = 0
if ymin < 0:
ymin = 0
if xmax > frame.shape[1]:
xmax = frame.shape[1]
if ymax > frame.shape[0]:
ymax = frame.shape[0]
# 顔領域のみ切り出し
frame_face = frame[ ymin:ymax, xmin:xmax ]
# 入力データフォーマットへ変換
img = cv2.resize(frame_face, (64, 64)) # サイズ変更
img = img.transpose((2, 0, 1)) # HWC > CHW
img = np.expand_dims(img, axis=0) # 次元合せ
img2 = cv2.resize(frame_face, (62, 62)) # サイズ変更
img2 = img2.transpose((2, 0, 1)) # HWC > CHW
img2 = np.expand_dims(img2, axis=0) # 次元合せ
# 推論実行(感情)
out = exec_net_emotion.infer(inputs={'data': img})
# 推論実行(性別・年齢)
out2 = exec_net_gender.infer(inputs={'data': img2})
# 出力から必要なデータのみ取り出し
out = out['prob_emotion']
out = np.squeeze(out) # 不要な次元の削減
age = out2['age_conv3']
gender = out2['prob']
age = np.squeeze(age) # 不要な次元の削減
gender = np.squeeze(gender) # 不要な次元の削減
# 年齢取得
age = int(age * 100)
# 性別取得
gender_labels = ['Female', 'Male']
gender_rate = int(gender[gender.argmax()]*100)
gender = gender_labels[gender.argmax()]
# 顔部分のロックオン画像表示
frame = overlayImage(frame, face_png, (xmin + int((xmax-xmin)/2)-98, ymin + int((ymax-ymin)/2) -102))
# 性別・年齢の表示画像を描画
frame = overlayImage(frame, gender_png, (490, 15))
# 性別・年齢のテキストを描画
text=str(gender) + ' [' + str(gender_rate) + '%]' + ' AGE : ' + str(age)
cv2.putText(frame, text, (530, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.56, (255, 255, 255), 1, cv2.LINE_AA)
# 感情分析の棒グラフを表示
rect_x = 180
rect_y = 333
for i in range(5):
cv2.rectangle(frame, (rect_x+1, rect_y+1), (rect_x + int(400 * out[i])+1, rect_y + 15+1), color=(0, 0, 0), thickness=1)
cv2.rectangle(frame, (rect_x, rect_y), (rect_x + int(400 * out[i]), rect_y + 15), color=(252, 255, 119), thickness=-2)
rect_y = rect_y + 24
# 枠フレーム画像を合成
frame = overlayImage(frame, frame_png, (0, 0))
# ファイル出力して終わり
cv2.imwrite(output_file_path, frame)上記サンプルプログラムの中で読み込んでいるPNG画像も、下記ボタンからダウンロードできるようにしておきます。ご自由にお使いください。
cd ~/
unzip image.zipダウンロードしたimage.zipをサンプルプログラムと同じディレクトリに展開してください。ここの例では、ホームディレクトリにサンプルプログラムとサンプル画像を展開しています。
ファイル展開後、次のようにpythonプログラムを実行してください。
python3 emotion.py -i sample.jpg -o result.jpg私の環境では実行完了まで15秒程度でした。result.jpgというファイルが出力されていれば成功です。
【評価】ラズパイによるNCS2ドーピング効果はいかに?

それでは、サンプルプログラムでAI分析した結果を見ていきたいと思います。
ラズパイ+NCS2 によるAI画像分析結果
ちょっぴりサイバーな感じに分析結果画像を出力するようにしてみました。
OpenCVデフォルトのフォントは正直イケてないので、雰囲気に合ったものにすべきですが、サンプルソースをこれ以上長くしたくなかったのでこの程度で妥協。
AIによる画像分析結果
- 性別: 女性(94%)
- 年齢: 21歳
- 感情: NEUTRAL(普通), HAPPY(幸せ) の要素が高め
こちらの学習モデルの仕様を見ると、年齢については18歳~75歳の範囲となっています。残念ながら小学生などの子供の場合、20歳とかになってしまいます。
OpenVINOには事前トレーニングされたさまざまなモデルが用意されています。各モデルの使い方は公式サイトのインタフェース情報を参照して使ってみましょう。

まとめ
細かい解説は、応用編などで別途記事にしたいと思います。まずは、動作するサンプルソースを改変しながら、面白い活用方法を考えて頂ければと思います。楽しみながらカスタマイズしちゃいましょう!
うちのスマートホームでは、来客者が来た場合にリアルタイムにインターフォン画像を分析させてLine Botに通知するようにしています。みなさんもAI分析結果の面白い活用方法を考えていきましょう♪



上記のラズパイ+カメラとNCS2の組み合わせもオススメです。
まとめ
- Raspberry PiのPythonでリアルタイムなAI分析処理が可能 ※多数のモデルが無料で使える
- 多数のAIモデルを眺めながら面白いアイデアを考えましょう
- Raspberry Pi 4とNCS2共に発熱に注意。ICE TOWERなど冷却効果大のファン併用がおすすめ
アイデア次第で面白いことがたくさんできると思います
(来客者の女性比率や平均年齢を調べたり・・・)
エッジコンピューティング?
Raspberry Piでエッジコンピューティングだ!といっても、画像・動画をネットワーク経由で転送した時点でもはやエッジではない気が・・・。ネットワークに繋がっていない閉域網に設置したRaspberry Piで活用したいところですが、今の時代どこでも高速なネットに繋がれますからね。