
こんにちは。画像編集が三度の飯より大好きなポン吉です。
スマートホームでカメラを活用したアプリを実装する場合、カッコよく魅せる画像編集がしたくなりますよね。そこで登場するのがOpenCV!プログラム初心者にとってOpenCVは難しいと感じるかもしれませんが、やりたいことを逆引きしてコピペで使えばいいんですよ!
OpenCVって何が出来るの?
初心者でも簡単に使えるの?


プログラム上で「画像処理」が簡単に実行できます!
機械学習する際にOpenCVは必須!
OpenCVのインストール方法からテクニカルな実用方法まで初心者~上級者まで幅広く使えるテクニックを紹介します。1行もプログラム書かずに動かせるサンプル集を公開しますのでパクって使い倒してください!
今回の記事を読めば「OpenCV+Python」による画像処理・動画編集のコツをマスターできるようになります。

OpenCVの「逆引きサンプル集」については、他記事で紹介したスマートホームアプリの実装例もあります。下記記事も合わせて参考にしてみてください。

今回のテーマはこちら!
- OpenCV(Python)のインストール方法を紹介 ※ラズベリーパイの環境構築例
- OpenCVによる画像処理テクニックを「逆引きサンプル集」として紹介
それではやってみましょう~♪
OpenCVでできること

OpenCVとは?
OpenCV(Open Source Computer Vision Library)とは、インテルが開発した画像処理ライブラリです。画像処理・画像解析・機械学習の各種機能を持っています。オープンソースで公開されているため、誰でも無料で使うことができます。インテルさんありがとうございます!
対象OSはPOSIXに準拠したUnix系OSになります。もちろんラズベリーパイでも使えます。C/C++, Java, Python, MATLABなど様々な言語用にライブラリが用意されています。本記事ではPythonでOpenCVを使う方法を紹介していきます。
OpenCVでできること
OpenCVでできることを簡単に紹介します。
- 画像や動画の「読み込み・編集・出力」といった基本操作
- 画像編集「拡大縮小」「トリミング」「画像合成」「回転」「3D変換」…etc
- AI物体検知「顔認識」「物体認識」「色識別」…etc












画像処理するだけであればOpenCVでなくても「NumPy」「Pillow」を直接使用することで、上記のような画像編集は可能ですが、Pythonベースの豊富なライブラリとOpenCVの組み合わせは非常に魅力的です。特に機械学習を行う際に画像の水増しや、画像分析する前の画像処理が必要になりますが、OpenCV+Pythonで簡単に処理する事ができます。
OpenCVのインストール

難易度:★☆☆☆☆
OpenCVは依存パッケージが多くインストールでハマる事が多いです。記事の内容をコピペするだけで動作できるように紹介します。本記事ではラズベリーパイでのインストール例となります。

ラズパイ自体も品薄で購入が難しい状況が続いています。ラズパイの在庫と価格をリアルタイム確認できるページを作りました。ラズパイを購入しようとしている方は是非参考にしてみてください。

Raspberry Pi に OpenCV環境をセットアップ
ラズベリーパイにOpenCVをインストールする方法を紹介します。OpenCVをラズベリーパイ上でmakeすると3時間以上もかかってしまいます。そこで、インストール時間を最小限にしつつ、シンプルに新しめのパッケージを入れる方法を紹介します。
注意
最新Raspberry Pi OS bullseye での構築例を紹介します。以前のRaspberry Pi OS buster等では python ⇒ python3 pip ⇒ pip3 と読み替えて実行してください。

ラズパイ初期セットアップの詳細は、上記記事を参照してください。
sudo apt update
sudo apt install -y python3-pip
sudo apt install -y libatlas-base-dev
sudo apt install -y libopencv-dev
pip install -U opencv-python
pip install -U numpy
pip install -U pillowコピーボタンを押してコンソールに貼り付けてインストールしましょう。最後の行のpillowは画像処理をする際に必要になる場面が多いので、OpenCVと一緒に入れておきます。
所要インストール時間
初期セットアップ済みのRaspberry Pi 4 でデスクトップ(GUI版)で約6分、デスクトップなし(CUI版)Liteで約10分ほどかかります。
インストール時に下記警告が出ますが無視してOK!「$HOME/.local/bin」にパスが通っていないが大丈夫か?」という警告。そもそもf2pyとか使いません。気になる方はパスを通してください。
WARNING: The scripts f2py, f2py3 and f2py3.9 are installed in '/home/ponkichi/.local/bin' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
次にOpenCVが正しくインストールできているか動作確認します。下記のようにコンソールから「python」と入力してEnterキーを押しましょう。「>>>」と表示されPythonインタプリタモードの対話形式になります。
ponkichi@raspberrypi:~ $ python
Python 3.9.2 (default, Feb 28 2021, 17:03:44)
[GCC 10.2.1 20210110] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> ← ここに何も表示されなければ正常です
ponkichi@raspberrypi:~ $ ここで「import cv2」と入力してEnterキーを押します。ここでエラーが出なければインストール成功です。CTRL+Dを押して終了させます。
今後のパッケージ最新化に伴い、本手順通りに実施しても動かなくなる可能性もあると思います。エラー発生時の対処方法について下記にまとめておきますので参考にしてみてください。
import cv2 エラー発生時の対処方法
OpenCVとPythonによる画像処理のテクニック「逆引きサンプル集」

私がこれまでアプリケーションを作っていて「これが出来れば大抵のやりたいことが実装できる」という内容に絞って紹介します。
OpenCVについてやりたいことを検索しても
上手く検索できずイライラする!ムキー!
私もこれまで情報収集に相当な時間を費やしました…
こちらの「逆引きサンプル集」をぜひ活用してください
「フリー写真素材サイト:ぱくたそ」さんから素敵なお姉さんの画像を使わせていただきます。以下、次の画像「 sample_girl.jpg 」をサンプルとして加工していきます。

画像ファイルの読み込み・書き込み
cv2.imread 関数
画像ファイルを読み込みます
例:color_image = cv2.imread("sample_girl.jpg", cv2.IMREAD_COLOR)
- 返り値: 画像のNumPy配列情報を返す(色管理情報はBGRになります)
- 第1引数: 読み込む画像ファイルを指定 (フルパス指定も可能)
- 第2引数: 読み込むオプションを指定
| 読み込みオプション | 説明 |
| cv2.IMREAD_COLOR | 画像をカラー情報で読み込みます ※透過情報なし |
| cv2.IMREAD_GRAYSCALE | 画像をグレースケール(白黒)で読み込みます |
| cv2.IMREAD_UNCHANGED | 画像をカラー情報+透過情報で読み込みます |
cv2.imwrite 関数
画像をファイルに書き込みます
例:cv2.imwrite("gray.jpg", gray_image)
- 第1引数: 書き込む画像ファイル名を指定 (フルパス指定も可能)
- 第2引数: 書き込む画像を指定
import cv2
# 3種類の画像の読み込み方「カラー、グレースケール、透過カラー」があります
color_image = cv2.imread("sample_girl.jpg", cv2.IMREAD_COLOR)
gray_image = cv2.imread("sample_girl.jpg", cv2.IMREAD_GRAYSCALE)
alpha_image = cv2.imread("sample_girl.jpg", cv2.IMREAD_UNCHANGED)
# グレースケールとして読み込んだ画像をファイルに出力
cv2.imwrite("gray.jpg", gray_image)

基本的には、JPEG画像の読み込みでは「cv2.IMREAD_COLOR」、透過PNG画像の読み込みでは「cv2.IMREAD_UNCHANGED」を使うと覚えておきましょう。
imread関数によるグレー化
imread関数によるグレースケール読み込みは、OSのエンコーダー依存の処理になります。よって、実行するOS環境によってグレースケール画像の出力結果が変わってしまうリスクがあります。
画像をグレー化したい場合はカラー画像として読み込んだ後に
cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)で変換するのを推奨
画像をデスクトップ上のウインドウに表示する
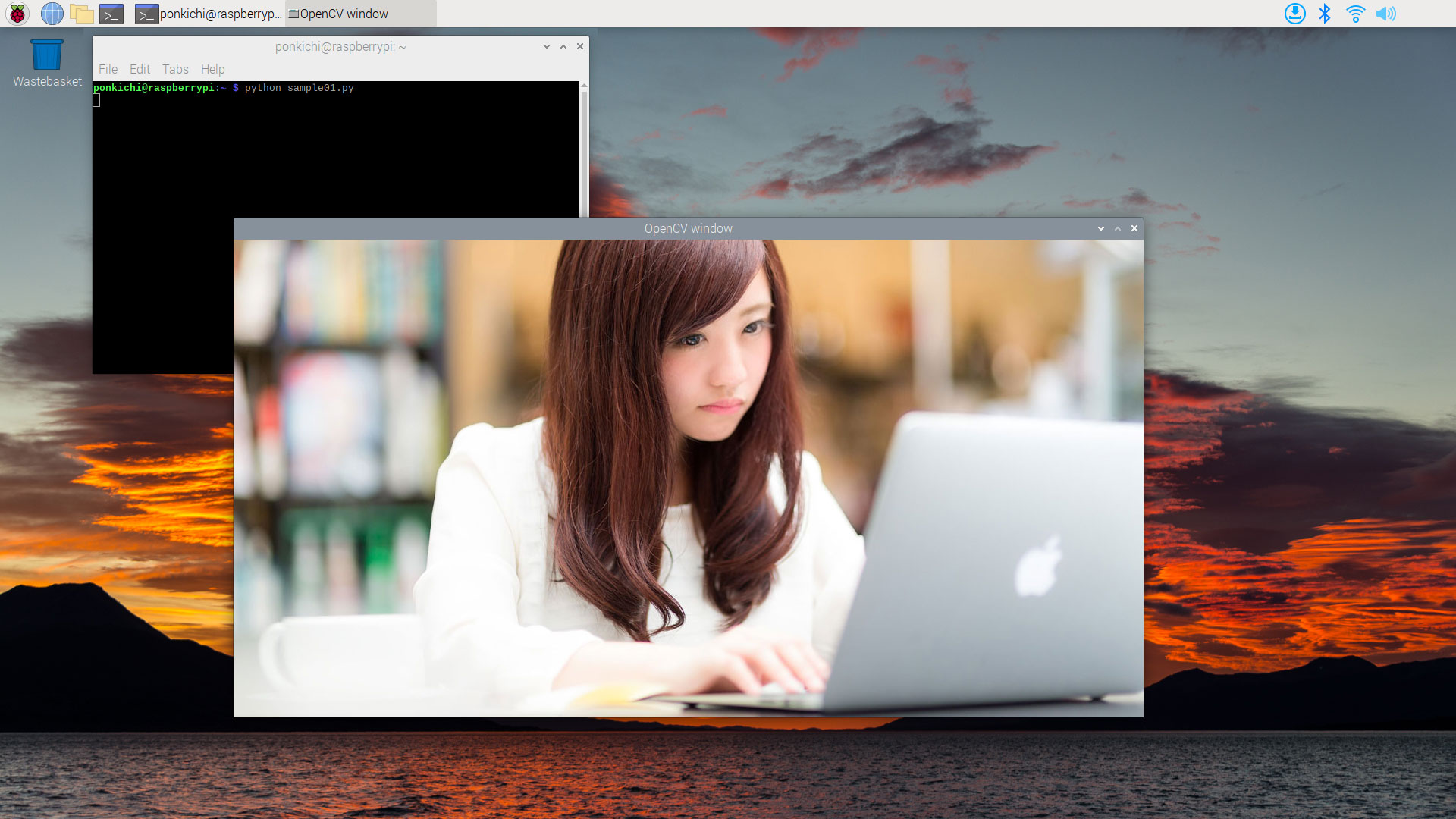
cv2.imshow 関数
画像ファイルをデスクトップ上のウインドウに表示します
例:cv2.imshow("OpenCV window", image)
- 返り値: 画像のNumPy配列情報を返す(色管理情報はBGRになります)
- 第1引数: デスクトップ上のウインドウ名称を指定
- 第2引数: 表示したい画像を指定
import cv2
# 画像の読み込み
image = cv2.imread("sample_girl.jpg", cv2.IMREAD_COLOR)
# カラー画像として読み込んだ画像をWindowsに表示
cv2.imshow("OpenCV window", image)
# 何かキーが押されたら終わる
cv2.waitKey(0)
cv2.destroyAllWindows()cv2.waitKeyは何かキーが押されるまで待つ関数です。これがないと即プログラムが終了しウインドウが閉じられるため入れています。特に画像処理とは関係ありません。
画像情報を取得する

shape メソッド
読み込んだ画像情報を取得します
例:height, width, ch = image.shape
- 返り値: 画像の「高さ, 幅, チャンネル数」の配列を返す
グレースケールではチャンネル数自体の
返り値が「なし」となるので注意
import cv2
# 画像の読み込み
image = cv2.imread("sample_girl.jpg", cv2.IMREAD_COLOR)
# 画像の高さと幅を取得
height, width, ch = image.shape
# 取得した情報を表示
print("高さ", height)
print("幅", width)
print("チャンネル数", ch)
実行結果
高さ 630
幅 1200
チャンネル数 3画像サイズを変更する

(200×105)
画像解像度が高いと画像処理が重くなります。特に、カメラ動画などをリアルタイム処理させる場合は、画像サイズを縮小することで処理を軽く出来るので覚えておきましょう。また、AI画像分析に掛ける際にも画像サイズを変更する必要があるため、画像サイズ変更の使用頻度は高めです。
cv2.resize 関数
画像サイズを変更します
例:output_image = cv2.resize(image, (200,105))
- 返り値: サイズ変更後の画像(NumPy配列情報)を返す
- 第1引数: 変更する対象画像を指定
- 第2引数: 変更したいサイズ情報を指定(幅,高さ)
import cv2
# 画像の読み込み
image = cv2.imread("sample_girl.jpg", cv2.IMREAD_COLOR)
# 画像サイズの変更
output_image = cv2.resize(image, (200,105))
# サイズ変更した画像をファイルに出力
result = cv2.imwrite("resize.jpg", output_image)画像を回転させる(90度刻み)

cv2.ROTATE_90_CLOCKWISE


cv2.ROTATE_90_COUNTERCLOCKWISE
正直あまり使わないと思いますが一応紹介。カメラ設置に物理的制約がある場合、プログラム側で回転させるケースで使います。
cv2.resize 関数
画像を回転させます
例:output_image = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
- 返り値: 回転させた画像(NumPy配列情報)を返す
- 第1引数: 回転させる対象の画像を指定
- 第2引数: 回転オプションを指定
| 回転オプション | 説明 |
| cv2.ROTATE_90_CLOCKWISE | 時計回りに90度回転させます |
| cv2.ROTATE_90_COUNTERCLOCKWISE | 反時計回りに90度回転させます |
| cv2.ROTATE_180 | 180度回転させます |
import cv2
# 画像の読み込み
image = cv2.imread("sample_girl.jpg", cv2.IMREAD_COLOR)
# 画像を時計回りに90度回転
output_image = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
# 回転させた画像をファイルに出力
result = cv2.imwrite("rotate.jpg", output_image)画像に透過PNG画像を重ねる

-透過PNGイメージ-
OpenCVには直接透過PNGを重ねる関数やメソッドは存在しません。透過PNG画像を重ねる「overlayImage関数」を自作しましょう。
個人的には一番使う画像編集処理です
overlayImage 関数
透過画像を合成します ※自作関数です
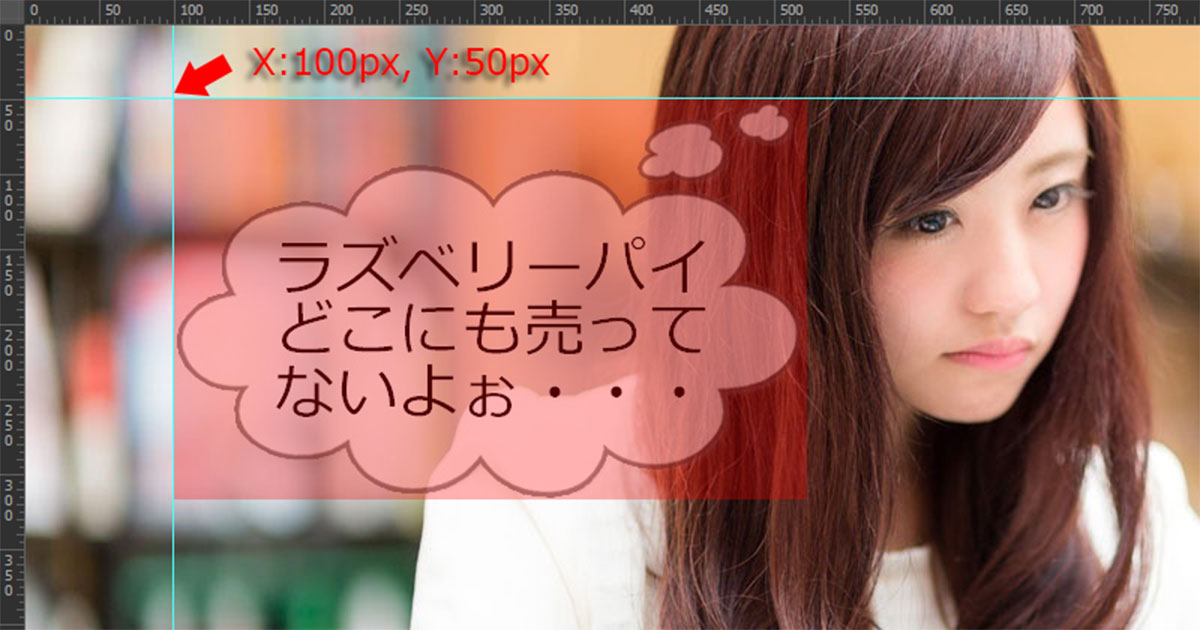
例:output_image = overlayImage(input_image, fukidashi_image, (100,50))
- 返り値: 合成した画像(NumPy配列情報)を返す
- 第1引数: 「背景画像」を指定
- 第2引数: 「透過画像」を指定
- 第3引数: 透過画像を貼り付ける「座標」を指定
import cv2
import numpy as np
from PIL import Image
# 透過画像を合成する関数
def overlayImage(src, overlay, location):
overlay_height, overlay_width = overlay.shape[:2]
# 背景をPIL形式に変換
src = cv2.cvtColor(src, cv2.COLOR_BGR2RGB)
pil_src = Image.fromarray(src)
pil_src = pil_src.convert('RGBA')
# オーバーレイをPIL形式に変換
overlay = cv2.cvtColor(overlay, cv2.COLOR_BGRA2RGBA)
pil_overlay = Image.fromarray(overlay)
pil_overlay = pil_overlay.convert('RGBA')
# 画像を合成
pil_tmp = Image.new('RGBA', pil_src.size, (255, 255, 255, 0))
pil_tmp.paste(pil_overlay, location, pil_overlay)
result_image = Image.alpha_composite(pil_src, pil_tmp)
# OpenCV形式に変換
return cv2.cvtColor(np.asarray(result_image), cv2.COLOR_RGBA2BGRA)
# 女性の画像(透過なしJPG)
input_image = cv2.imread("sample_girl.jpg", cv2.IMREAD_COLOR)
# 吹き出し(透過PNG)
fukidashi_image = cv2.imread("fukidashi.png", cv2.IMREAD_UNCHANGED)
# 吹き出しの透過PNG画像を被せる
output_image = overlayImage(input_image, fukidashi_image, (100,50))
# 合成した画像をファイルに出力
cv2.imwrite("mix.jpg", output_image)
第3引数の「貼り付け先の座標」のイメージ図はこちら。このサンプル例では(X座標:100px, Y座標:50px)となっています。
おすすめのユースケース
- ラズパイで作ったロボット・ドローンのHUD(ヘッドアップディスプレイ)実装
- ディープラーニング分析結果を半透明画像として未来感あふれる画像に加工
要約すると「なんかカッコよく情報を画像に表示したい!」時に使いましょう!
2枚の画像を重みを指定して重ね合わせる


ここでは透過PNG画像の貼り付けではなく、2つの画像の重み(比率)を指定して合成する方法を紹介します。このサンプルは、「ドローンでほこり掃除を自動化」で紹介した動画処理の例として紹介します。
エヴァンゲリオン風の画像は「単純な図形」と
「明朝フォント」を使うだけなので作成が楽ちん!
オリジナルデザインにしろよ!
cv2.addWeighted 関数
2つの画像を重みを指定してアルファブレンド合成します
例:output_image = cv2.addWeighted(emergency_image, 0.25, input_image, 0.75, 0)
- 返り値: 合成した画像(NumPy配列情報)を返す
- 第1引数: 合成画像1を指定
- 第2引数: 合成画像1の重みを指定
- 第3引数: 合成画像2を指定
- 第4引数: 合成画像2の重みを指定
- 第5引数: 合成時のガンマ値(明るさ)を指定
第5引数のガンマ値(コンストラスト)はあまり変化を感じないので0でよいかと
import cv2
# 入力元の画像と重ねる画像の2つを読み込み
input_image = cv2.imread("drone_crush.jpg", cv2.IMREAD_COLOR)
emergency_image = cv2.imread("emergency.jpg", cv2.IMREAD_COLOR)
# EMERGENCY画像を25%, 元画像を75%の比率で画像を合成
output_image = cv2.addWeighted(emergency_image, 0.25, input_image, 0.75, 0)
# 合成した画像をファイルに出力
cv2.imwrite("output.jpg", output_image)参考までにアルファ値を変更した場合の見え方についても載せておきます。


画像を3Dっぽく変換する(透視変換/射影変換)

平面の画像を無駄に斜めにするだけで3Dのようにリアルでカッコよくなります! ※個人差あり
cv2.getPerspectiveTransform 関数
透視変換を行うための変換行列を作成します
例:M = cv2.getPerspectiveTransform(pts1,pts2)
- 返り値: 透視変換に使う変換行列を返す
- 第1引数: 変換前の4点の座標情報を指定
- 第2引数: 変換後の4点の座標情報を指定
cv2.warpPerspective 関数
透視変換(3Dっぽく歪める)を行います
例:output_image = cv2.warpPerspective(input_image, M, (cols, rows))
- 返り値: 透視変換後の画像(NumPy配列情報)を返す
- 第1引数: 対象とする画像を指定
- 第2引数: 変換行列を指定
- 第3引数: 出力する画像サイズを指定
import cv2
import numpy as np
# 入力画像の読み込み
input_image = cv2.imread("eva_drone.jpg", cv2.IMREAD_COLOR)
# 入力画像のサイズ取得(rowsが幅, colsが高, chのチャンネル数は今回未使用)
rows,cols,ch = input_image.shape
# 透視変換で画像を歪ませる座標を指定[pts1:変更前, pts2:変更後]
pts1 = np.float32([[0,0],[cols,0],[0,rows],[cols,rows]])
pts2 = np.float32([[0,300],[2026,0],[323,1091],[2077,1236]])
M = cv2.getPerspectiveTransform(pts1,pts2)
# 透視変換の処理を実行
output_image = cv2.warpPerspective(input_image, M, (cols, rows))
# 変換した画像をファイルに出力
result = cv2.imwrite("result_affine.jpg", output_image)12~13行目の座標の指定値がややわかりづらいので、透過変換のイメージ図を描いてみました。

今回は「わかりやすさ重視」で変換前座標を元画像の4隅の座標に指定しましたが、画像エリアの任意座標で指定可能です。いろいろ試してみましょう。本来は「歪んだ画像」を「綺麗な長方形」として取り出す用途に使うのがメインだと思います。
こちらの画像処理を実際に組み込んだドローン自動化の記事もよろしければ参照してみてください。

テキストを描画する(標準フォント使用)


cv2.putText 関数
画像にテキストを描画します
例:cv2.putText(image, text , (100, 200), font, font_size, font_color, font_thickness, font_lineType)
- 第1引数: 「背景画像」を指定
- 第2引数: 「テキストの文字列」を指定
- 第3引数: 「座標」を指定
- 第4引数: 「フォント種類」を指定 ※指定値は下記の図を参照
- 第5引数: 「フォントサイズ」を少数で指定
- 第6引数: 「フォントの色」をGBRで指定
- 第7引数: 「フォントの太さ」を整数で指定
- 第8引数: 「フォントのアルゴリズム」を指定 ※cv2.LINE_AA指定を推奨
| フォントの種類 | 説明 |
| cv2.FONT_HERSHEY_SIMPLEX | 図の表示イメージを参照 |
| cv2.FONT_HERSHEY_PLAIN | |
| cv2.FONT_HERSHEY_DUPLEX | |
| cv2.FONT_HERSHEY_COMPLEX | |
| cv2.FONT_HERSHEY_TRIPLEX | |
| cv2.FONT_HERSHEY_COMPLEX_SMALL | |
| cv2.FONT_HERSHEY_SCRIPT_SIMPLEX | |
| cv2.FONT_HERSHEY_SCRIPT_COMPLEX |
| フォントのアルゴリズム | 説明 |
| cv2.LINE_AA | アンチエイリアス指定で滑らかな文字表示に |
| cv2.LINE_4 | 4連結 |
| cv2.LINE_8 | 8連結 |
import cv2
# 入力画像の読み込み
image = cv2.imread("EINSTEIN.jpg", cv2.IMREAD_COLOR)
# 描画するテキスト文字列(日本語は使えません)
text1 = "Once you stop learning,"
text2 = "you start dying."
text3 = "- Albert Einstein -"
# 描画するフォントの設定
font_type = cv2.FONT_HERSHEY_SIMPLEX
font_size = 2.0
font_color = (255, 255, 255)
font_thickness = 2
font_lineType = cv2.LINE_AA
# 画像にテキストを描画
cv2.putText(image, text1 , (220, 185), font_type, font_size, font_color, font_thickness, font_lineType)
cv2.putText(image, text2 , (220+120, 185+60), font_type, font_size, font_color, font_thickness, font_lineType)
cv2.putText(image, text3 , (220+60, 185+170), font_type, font_size, font_color, font_thickness, font_lineType)
# テキストを描画した画像をファイルに出力
result = cv2.imwrite("text.jpg", image)OpenCVのデフォルトで使えるフォントはHERSHEYというものに限られています。フォント種別ごとの描画イメージは下記の図を参照してみてください。ちなみに日本語テキストは描画できません。
上記の上3つ以外のフォントについては、「 cv2.FONTHERSHEY_COMPLEX | cv2.FONT_ITALIC 」のように指定すると、フォントがイタリックになります。すべてのフォントがイタリックに出来るわけではないので注意しましょう。
日本語も描画できずデザインもイケてないので
次に紹介する「外部フォント使用」を推奨・・・
使わないなら紹介すんなよ!!
注意
テキストを挿入する座標は「テキストの左下座標」を指定します。画像貼り付け座標などで一般的に使われれる「左上座標」ではないので注意。
テキストを描画する(外部フォント使用) ※こちら推奨
ImageFont.truetype 関数
フォントファイルを読み込みます
例:font = ImageFont.truetype('MPLUS1p-Regular.ttf', 48)
- 返り値: フォントオブジェクトを返す
- 第1引数: ビットマップフォントファイルを指定
- 第2引数: フォントサイズを指定
import numpy as np
from PIL import Image, ImageFont, ImageDraw
# 入力画像の読み込み
input_image = cv2.imread("EINSTEIN.jpg", cv2.IMREAD_COLOR)
# フォントファイルを読み込み(Googleのフリーフォントを使用)
font = ImageFont.truetype('MPLUS1p-Regular.ttf', 48)
# 入力画像をPIL形式に変更してテキストを書き込み
image_pil = Image.fromarray(input_image)
draw = ImageDraw.Draw(image_pil)
draw.text((180, 185), "学ぶことを止めた時、それは死の始まり", font = font, fill = (255,255,255))
draw.text((210, 325), "- アルベルト・アインシュタイン -", font = font, fill = (255,255,255))
# PIL形式の画像をNumPy形式(OpenCV)に変換
output_image = np.array(image_pil)
# テキストを描画した画像をファイルに出力
result = cv2.imwrite("jp_font_text.jpg", output_image)今回はフリーの「Googleフォント」から「M PLUS 1p」という日本語フォントを使いました。

上記リンクからフォントをダウンロードしてください。'MPLUS1p-Regular.ttf' というファイルをPython実行プログラムと同じ場所にコピーして実行してください。
こちらの処理はpillowだけで実行できるものです。OpenCVの処理をさせながら日本語フォントを使いたいケースが多いと思いますので、あえてOpenCVの画像に対して処理するサンプルとしています。
注意
テキストを挿入する座標は「テキストの左上座標」を指定します。先ほどの座標と違うので注意。ややこしい・・・
仕様としてはこっちが正しい気がします
まとめ

OpenCVを活用してアイデアを形にしていこう!
今回紹介した「画像編集」や「テキスト処理」を組み合わせれば、大抵のやりたいことは実現できると思います。あとはアイデアを形にすべく、アプリ実装に励みましょう!皆さんのアイデア具現化の効率向上に少しでも役立てて頂けると嬉しいです。
最近はAIによる画像描画が流行ってきています。ラズパイでAIに絵を描かせる方法についても記事にしましたので、合わせて読んでみてください。

まとめ
- OpenCVはプログラムから画像処理する上で必須!スキルを身に着けよう
- OpenCVのインストール時には関連依存パッケージ不足に注意!
- 透過処理や射影変換を活用して「カッコよく」未来感ある画像に仕上げよう
「カッコいい」は正義! オリジナリティを演出しよう!
OpenCVを活用したスマートホームやラズパイの関連記事についても参考にしてみてください。



OpenCVと機械学習の関係
OpenCVと機械学習は切っても切れない関係にあります。まずは基本的なスキルを身につけて、次のステップとして機械学習にチャレンジしましょう。機械学習といっても「学習済みモデル」を使うだけであればコピペで誰でも簡単にできる時代です。